Centre for Vision, Speech and Signal Processing, University of Surrey, UK
Our method decomposes spatial reference resolution into two stages. An Index Proposal Network (IPN) first detects whether a gloss-aligned pose segment constitutes an indexing sign. Detected mentions are then passed to an Entity Linking Module (ELM), an online differentiable memory that incrementally clusters index mentions into discourse entities across the document. At inference time, both outputs are injected as additive logit biases into a frozen CSLR backbone.
Each segment is represented by 3D skeletal pose extracted from RGB video: 8 upper-body joints from SMPL-X and 21 joints per hand from WiLoR (42 hand joints total), normalised for scale and viewpoint to support cross-dataset generalisation. These features are processed by an SL-GCN to produce a segment-level embedding.
A strong retrieval-based CSLR model (CSLR2) achieves competitive overall WER but recovers indexing tokens poorly. After reinserting excluded non-lexical segments (GIS) into evaluation, WERIndex reaches 98.4% and Index IoU drops to 6.1%, motivating an explicit indexing expert.
| System | Index IoU (%) | WERAll (%) | WERIndex (%) | WERLex (%) |
|---|---|---|---|---|
| BLLexical | 15.8 | 69.5 | 91.3 | 77.5 |
| BLIndexRestored | 6.1 | 70.5 | 98.4 | 77.5 |
WERLex excludes pointing-token vocabulary; WERIndex is computed over the pointing sub-vocabulary only.
The IPN generalises across sign languages (BSL ↔ DGS), and joint training (B+M) consistently outperforms single-corpus models on held-out sets. A precision-calibrated variant (cw4, threshold 0.90) is used for downstream CSLR integration to suppress false-positive bleed.
| Train | Eval | BalAcc | Macro F1 | Prec-I | Rec-I |
|---|---|---|---|---|---|
| B | B | 0.85 | 0.85 | 0.85 | 0.85 |
| M | 0.76 | 0.76 | 0.72 | 0.86 | |
| BOB | 0.77 | 0.68 | 0.35 | 0.66 | |
| M | B | 0.75 | 0.74 | 0.87 | 0.58 |
| M | 0.87 | 0.87 | 0.87 | 0.88 | |
| BOB | 0.72 | 0.70 | 0.41 | 0.52 | |
| BM-cw4 | B | 0.82 | 0.81 | 0.91 | 0.70 |
| M | 0.85 | 0.85 | 0.90 | 0.79 | |
| BOB | 0.73 | 0.72 | 0.47 | 0.52 | |
| BM | B | 0.85 | 0.85 | 0.88 | 0.82 |
| M | 0.87 | 0.87 | 0.86 | 0.88 | |
| BOB | 0.78 | 0.69 | 0.37 | 0.68 |
B = BSLCP, M = MDGS, BOB = BOBSL. Mean over 3 seeds, threshold = 0.5.
Joint training on BSLCP+MDGS yields slightly higher Entity Cluster Accuracy (0.65 vs. 0.62) but comparable F1. However, BSLCP-only ELM training achieves lower downstream WER on BOBSL, so it is used for CSLR integration.
| IPN Model | ELM Source | ECA (B) | F1 (B) | WERAll (BOB) | WERLex (BOB) | WERIndex (BOB) |
|---|---|---|---|---|---|---|
| BM-cw4 | B | 0.62 ±0.02 | 0.44 ±0.01 | 70.1 | 78.4 | 64.3 |
| BM-cw4 | B+M | 0.65 | 0.43 ±0.01 | 70.2 | 78.4 | 64.7 |
ECA = entity cluster accuracy on BSLCP test set. WER reported at wIPN=10, wELM=60.
The grid search sweeps detection boost weight (wIPN) and entity linking boost weight (wELM). Increasing wIPN is the primary driver of WERIndex reduction; wELM provides consistent additional gains. However, high wIPN causes lexical bleed, creating a trade-off that produces a visible valley in WERAll around wIPN ≈ 8. The selected operating point wIPN=8, wELM=10 reduces WERIndex from 96.3 to 59.6 and WERAll from 70.5 to 68.3, while leaving WERLex stable.
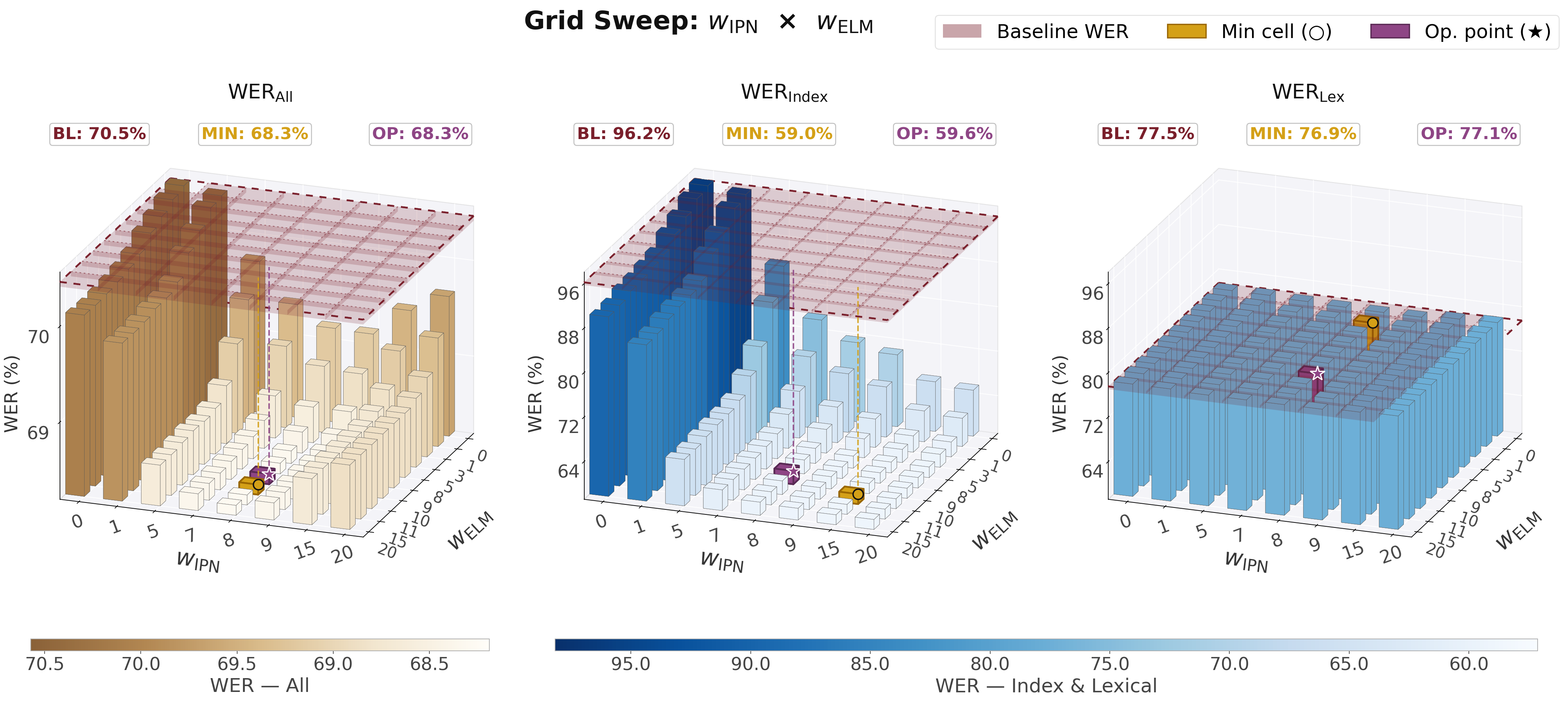
| Config | WERAll (%) | WERIndex (%) | WERLex (%) |
|---|---|---|---|
| Baseline (CSLR2 only) | 70.5 | 96.3 | 77.4 |
| No-memory (IPN only) | 69.1 | 66.5 | 76.9 |
| No-proposal (ELM only) | 70.1 | 89.5 | 77.4 |
| IPN + ELM (wIPN=8, wELM=10) | 68.3 | 59.6 | 77.1 |
Component ablation in CSLR2. No-memory retains index proposal detection but removes entity-linking memory; No-proposal removes detection but retains entity linking; IPN + ELM is the full system at wIPN=8, wELM=10.
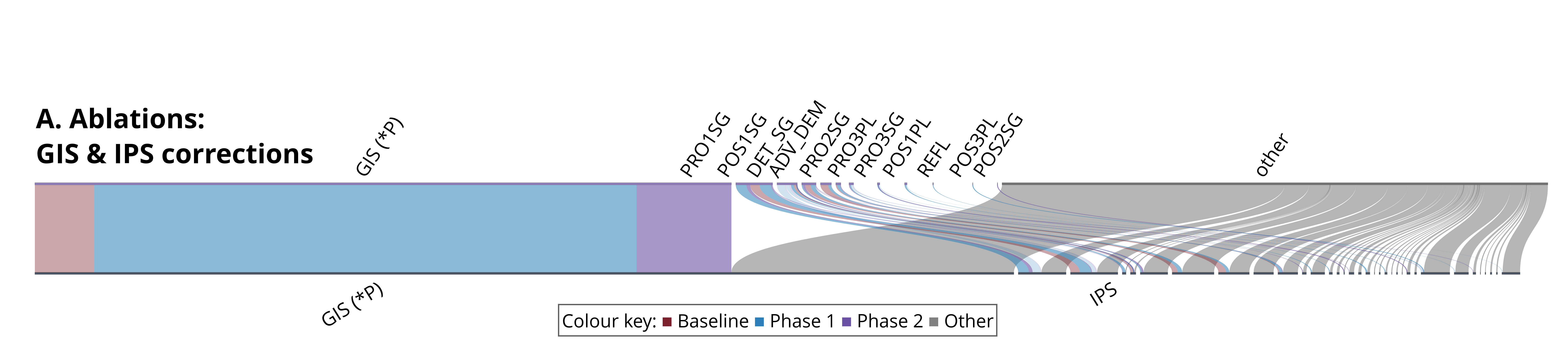
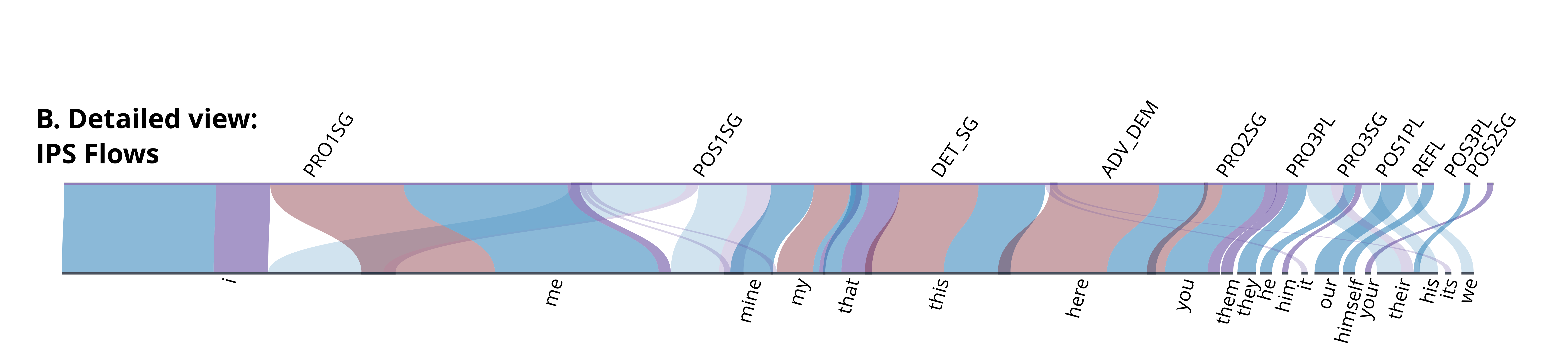
Each flow traces a ground-truth pointing token to the coarse referential class of the predicted token, grouped into pronoun and deictic categories. Under the baseline, only 6.1% of ground-truth index tokens are recovered. The IPN detection boost alone raises this to 61.5%, and the full system reaches 71.2%, confirming that entity linking provides a consistent gain on top of detection.
The top panel shows all GIS and IPS instances; the bottom panel isolates IPS tokens to highlight entity-specific behaviour.
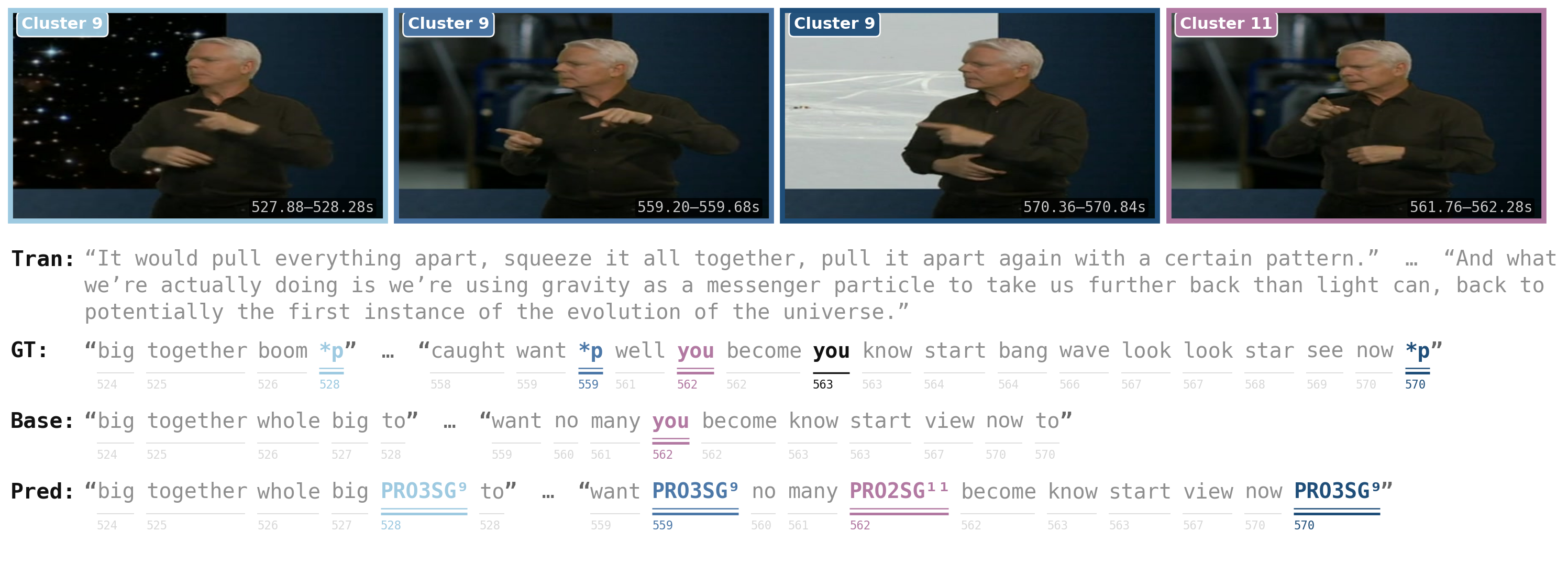
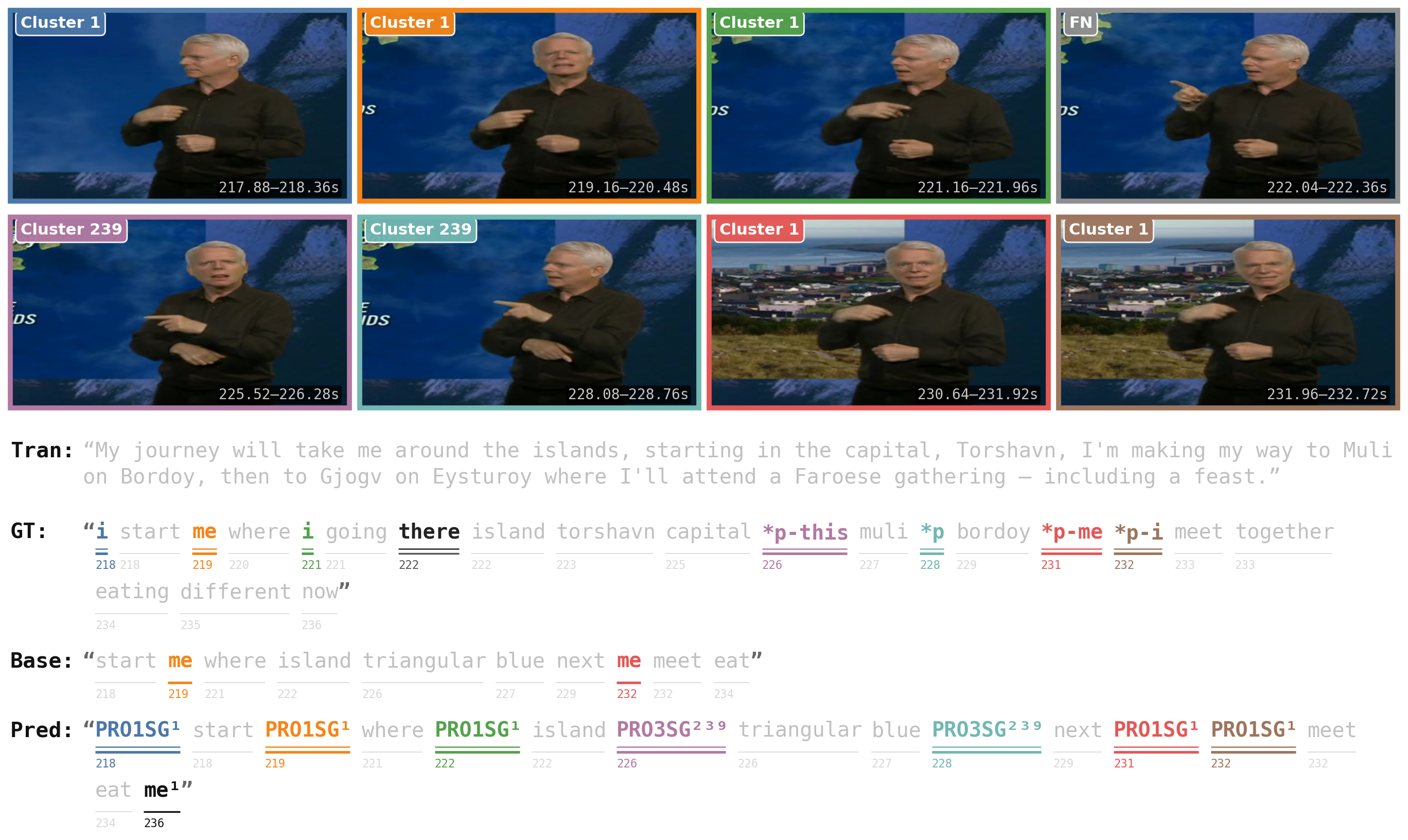
The figure below shows a qualitative example on BOBSL. The system resolves clusters across sentences and captures subtle pointing distinctions, separating a third-person singular entity from a second-person "you" reference. The base CSLR2 picked up only the "you" index sign and missed all third-person references.
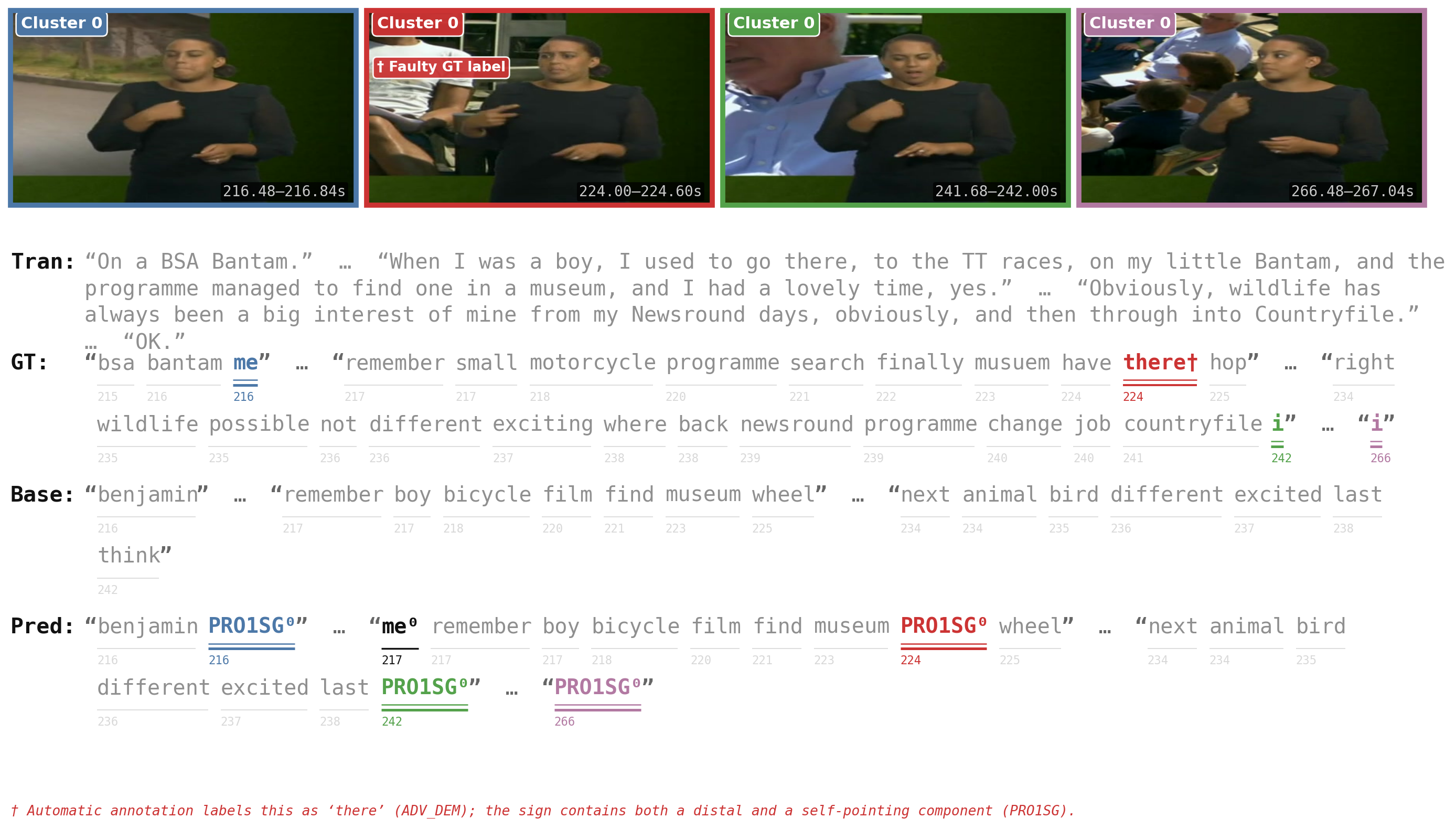
The following figures show predicted entity clusters on BOBSL alongside the subtitle text for each segment. Cluster structure is reflected in coherent lexical output and visual similarity across instances assigned to the same entity.
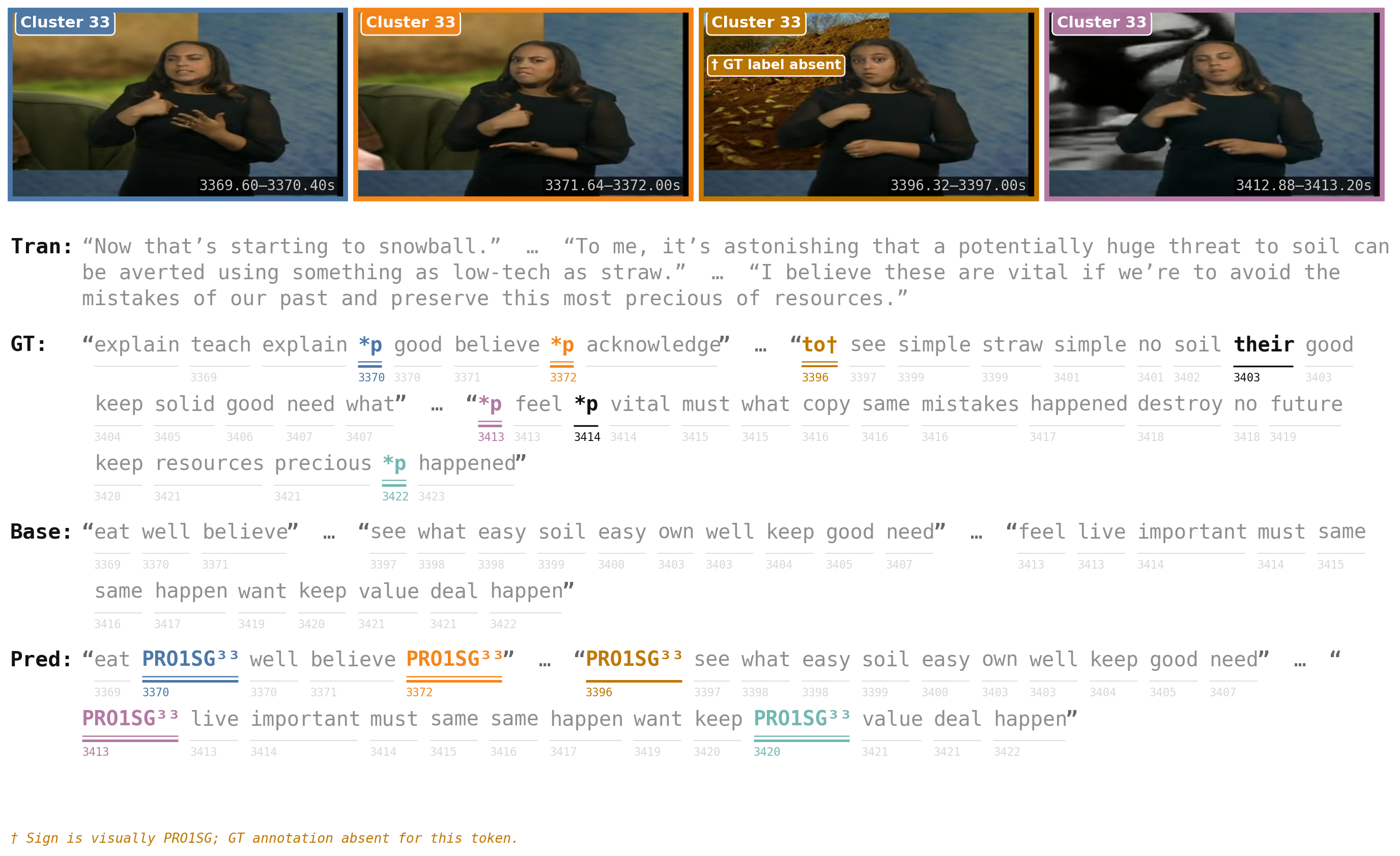
Red border = false positive (lexical sign predicted as index); blue border = false negative (pointing sign missed). FPs are largely systematic: mispredicted signs frequently exhibit index-like handshapes. FNs often arise from co-articulation with co-occurring lexical signs.
















@article{ranum2026whatsthepoint,
title = {What's the Point? Spatial Grammar \& Index Resolution
for Sign Language Recognition},
author = {Ranum, Oline and Hadfield, Simon and Bowden, Richard},
journal = {arXiv preprint arXiv:2606.08056},
year = {2026},
}