
SignGPT
 | Building Generative Predictive Transformers for Sign Language UKRI EPSRC Programme Grant · University of Surrey, University of Oxford, University College London · 2025–2031 |
📄 Preprint (PDF) · 🌐 SignGPT Project
Overview
SignGPT is a UKRI EPSRC Programme Grant bringing together specialists in machine vision, generative AI, and sign language linguistics from the University of Surrey, University of Oxford, and University College London, with direct involvement from Deaf organisations and community partners.
The project’s long-term vision is to build the first conversational sign language model for British Sign Language — analogous to what large language models have done for written text — enabling seamless, bidirectional communication between signing and hearing individuals. Unlike prior systems that treat signing as a derivative of spoken language, SignGPT treats BSL as deserving its own generative model, with the full complexity of signing built in from the ground up: spatial grammar, non-manual features, productive constructions, and signer variation.
The Problem
Progress in Sign Language Processing (SLP) is constrained not just by the scale of available data, but by its ecological validity — whether it actually reflects how sign languages are used in real communication.
Current data sources fall short. The vast majority of SLP datasets are drawn from interpreted broadcast media or web-scraped content. Interpreted signing is produced under live broadcast constraints and differs substantially from everyday Deaf communication — it routinely involves omissions, simplifications, and restructuring relative to the spoken source. Web-scraped material raises concerns around consent, copyright, and unknown signer proficiency.
Gloss annotations are both necessary and limiting. Glosses — approximate word-level transcriptions of manual signs — are the dominant supervision signal in SLP, but they are costly to produce and systematically incomplete. A single sign can carry multiple meanings depending on context; sociolinguistic variation means the same concept may be realised differently across signers. Crucially, glosses collapse or ignore the productive constructions that are central to sign grammar: pointing, depicting signs, spatial indexing, and classifiers. Only around 15% of the BSL Corpus has been annotated at all.
Sign languages are simultaneous and spatial, not sequential. Roughly 60% of spontaneous BSL consists of non-lexical elements — brow raises, eye gaze, mouthings, head movements, body posture — that interact simultaneously across multiple articulators to encode grammatical and prosodic meaning. The linear, token-based modelling paradigms inherited from spoken-language NLP are a structural mismatch for this, and standard evaluation metrics like BLEU fail to capture the compositional and spatial structure of signing.
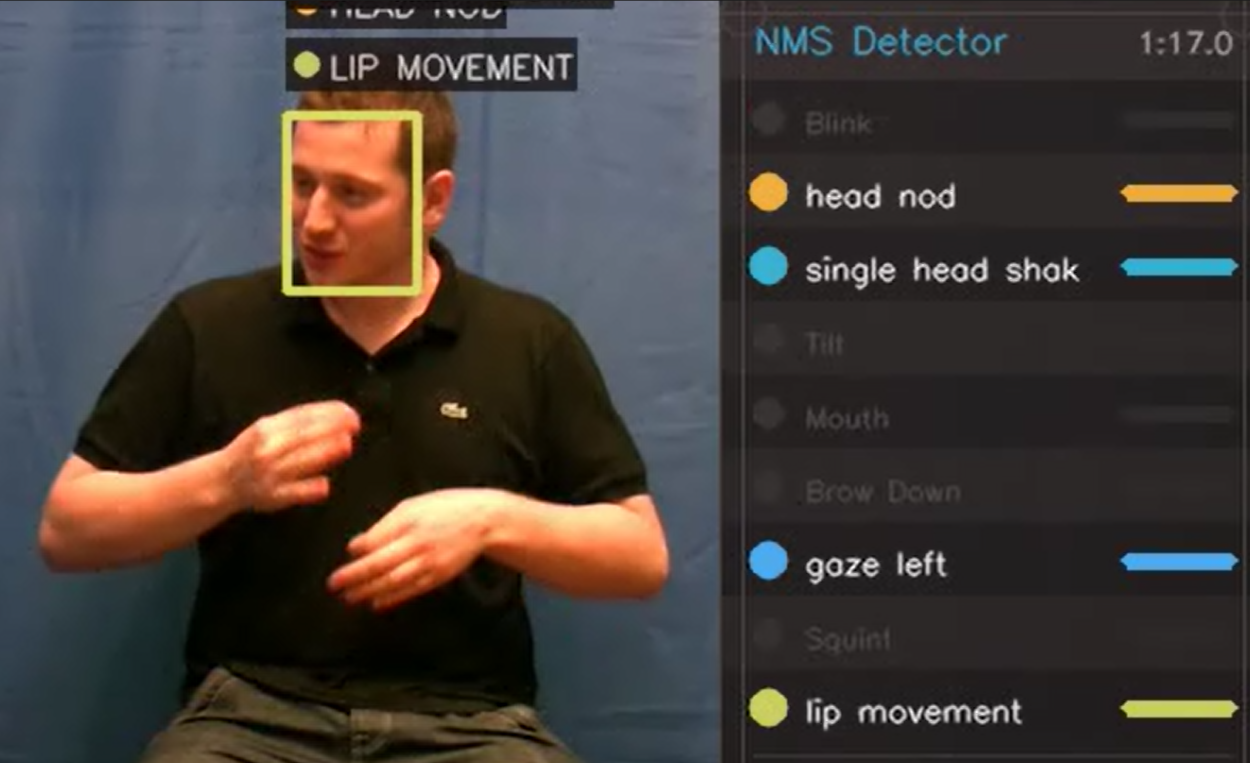
Evaluation remains underdeveloped. Most benchmarks measure sign-to-gloss or sign-to-text accuracy on interpreted, broadcast-derived data. This risks training models that are well-adapted to the artefacts of broadcast interpretation rather than to real-world signing. Advancing the field requires evaluation grounded in naturalistic, Deaf-produced data with linguistically principled annotation.
Visual Language Toolkit
To address these challenges, the project is developing the Visual Language Toolkit (VLT) — a modular suite of semi-automatic annotation tools designed to scale corpus development without sacrificing linguistic principles. Early tools cover sign segmentation, sign spotting, non-manual feature tracking, and 3D signer reconstruction, all interoperable with standard annotation platforms such as ELAN.
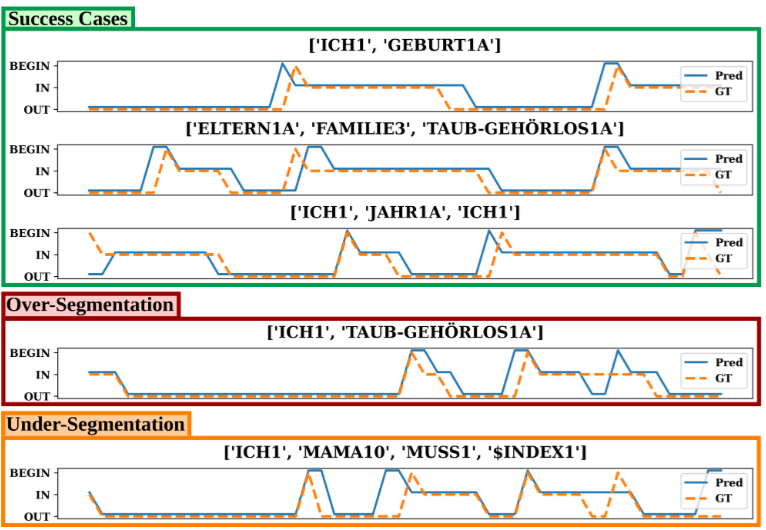 | 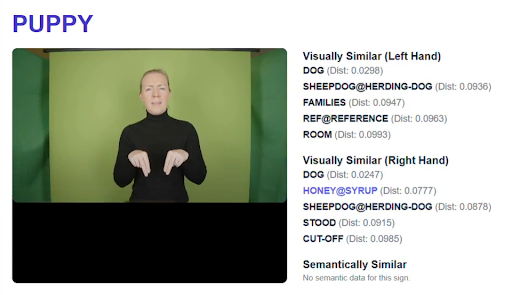 |
The VLT is under active development. Components will be released as open-source software accessible to researchers, linguists, and Deaf communities.
Publications
Brown, M., Ranum, O., Fish, E., Proctor, H., Woll, B., Bowden, R., Cormier, K. (2026). SignGPT and the Visual Language Toolkit. 12th Workshop on the Representation and Processing of Sign Languages: Language in Motion, LREC 2026, Palma de Mallorca, Spain.