
UKRI EPSRC Programme Grant · 2025–2031
SignGPT
University of Surrey · University of Oxford · University College London
University of Surrey · University of Oxford · University College London
SignGPT is a six-year UKRI EPSRC Programme Grant (2025–2031) bringing together researchers from the University of Surrey, University of Oxford, and University College London to tackle one of the hardest open problems in AI: unconstrained, bidirectional translation between Sign Language and spoken language, focusing on BSL and English. The project spans computer vision, sign linguistics, and machine learning, and is developed in close collaboration with Deaf organisations and community partners.
The central goal is to build the first large-scale generative model for sign language — a SignGPT — trained on a dataset larger than anything previously assembled for a signed language. Rather than treating BSL as a derivative of English or reducing it to sequences of isolated signs, the project is designed around the full structure of signed communication: its spatial grammar, simultaneous multi-articulator organisation, and the breadth of variation across Deaf signers. Alongside the core model, the project is developing a Visual Language Toolkit — a suite of open tools for annotation, language learning, and automatic interpretation — intended to serve both the research community and the wider Deaf community directly.
SLP research has grown rapidly over the last decade, with the field largely concentrating on three primary tasks — recognition, production, and translation — typically operating on video data with gloss annotations or free-text translations as supervision. Sign-to-text translation has commonly been treated as a pipeline problem: recognition feeds into gloss-level representations, which are then translated to spoken language text.
More recent work has introduced gloss-free approaches that model sign-to-text mapping end-to-end without gloss intermediaries. However, both paradigms tend to prioritise mapping surface-level manual features to spoken language text, often without capturing the full compositional and multimodal structure of signed communication. Text-to-sign research similarly concentrates on surface-level appearance rather than linguistic composition, and evaluation typically relies on metrics such as BLEU that are poorly suited to the spatial and simultaneous structure of signing. Advancing the field requires rethinking not just the models, but the data, representations, and evaluation criteria that underpin them.
SLP datasets largely consist of interpreted broadcasts, social media content, or curated corpora — each with significant limitations. Interpreted signing differs substantially from natural Deaf communication, web-sourced material raises consent and quality concerns, and only around 15% of the BSL Corpus has been annotated at all. Gloss annotations are the dominant supervision signal but are costly, incomplete, and systematically unable to capture productive constructions — pointing, depicting signs, spatial indexing — that are central to sign grammar.
Sign languages are not strictly linearly ordered — grammatical relations are distributed across space and expressed simultaneously across multiple articulators, rather than encoded one unit at a time. This is a fundamental mismatch with the sequential, token-based modelling paradigms inherited from spoken-language NLP. Linearised intermediate representations such as gloss strings or caption-aligned tokens introduce an information bottleneck that obscures spatial grammar, productive constructions, and flexible constituent ordering. A signed grammatical structure may correspond to multiple different spoken-language sequences, and vice versa — a variability that standard metrics such as BLEU are not designed to capture. Progress will likely require representations that treat simultaneity, space, and cross-articulator alignment as first-class properties rather than edge cases.
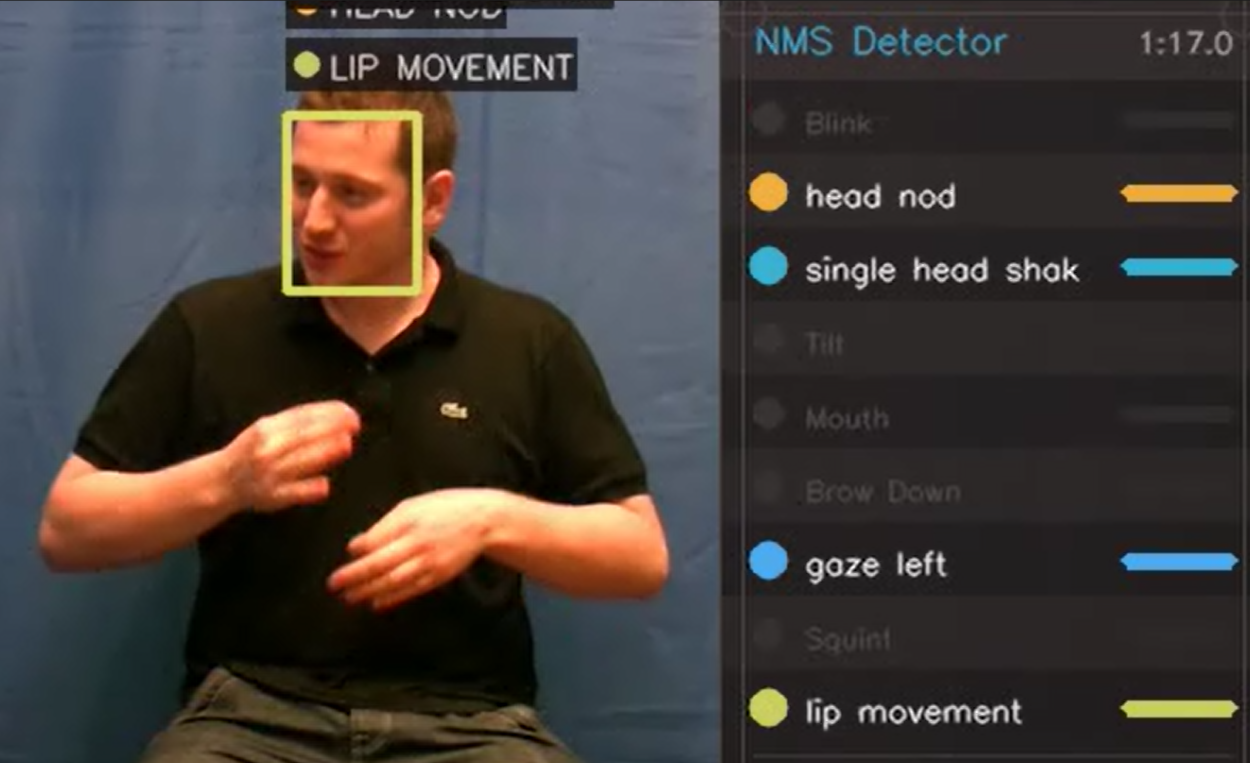
Non-manual signals — brow raises, eye gaze, mouthings, head movements, body posture — carry grammatical, prosodic, and discourse-level meaning simultaneously across articulators. Despite their fundamental role, most SLP approaches focus on coarse pose and motion, and work that does incorporate non-manual features remains relatively limited. Productive constructions — depicting signs, spatial indexing, classifier constructions — are similarly absent or reduced to coarse categories in gloss-based annotation, despite encoding grammatical information that is not expressible through lexical items alone. Many grammatical functions, including directionality and clause type marking, are conveyed through spatial and articulatory modulation rather than through discrete signs. Without modelling these dimensions, systems risk optimising for lexical recognition while missing the broader structure of the language.
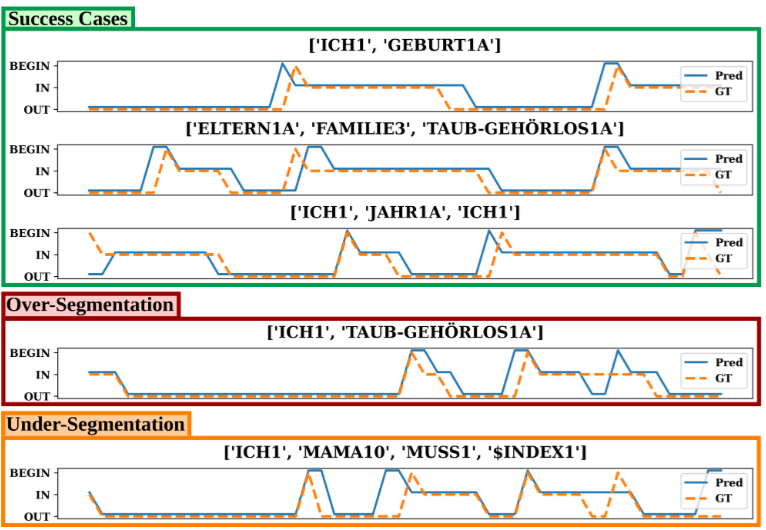
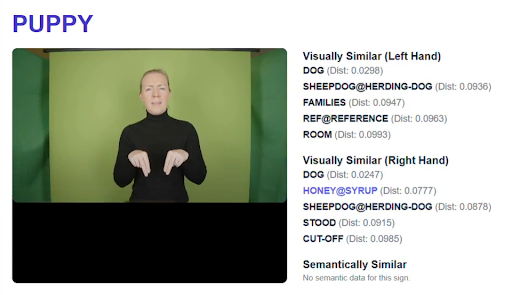
Real-world applicability requires moving towards fluent, ethically sourced, Deaf-produced conversational data — supported by scalable annotation tooling. Progress depends on modelling and evaluation approaches that reflect the multimodal, spatial, and simultaneous nature of sign language, enabling systems to handle signer variation and the full range of structures found in natural signing, rather than features optimised for broadcast-derived benchmarks.
To address these challenges, the project is developing the Visual Language Toolkit (VLT) — a modular suite of semi-automatic annotation tools designed to scale corpus development while preserving linguistic principles. Early tools cover sign segmentation, sign spotting, non-manual feature tracking, and 3D signer reconstruction, all designed for interoperability with ELAN. The VLT is under active early development and will be released as open-source software. Beyond annotation, planned capabilities include interfaces to large language models, sign language learning tools, and conversational applications — though the scope will evolve as the project matures.

Brown, M., Ranum, O., Fish, E., Proctor, H., Woll, B., Bowden, R., & Cormier, K. (2026). SignGPT and the Visual Language Toolkit. 12th Workshop on the Representation and Processing of Sign Languages: Language in Motion, LREC 2026, Palma de Mallorca, Spain. 📄 Preprint (PDF)